
Review: Build Your Own LLM Workshop
Last Saturday I attended a full-day “How to Build Your Own LLM Workshop,” hosted by Rally SF at The Commons. The course was taught by Justin Angel. Here’s my review.

Here we are at the Commons, deeply focused on Justin’s lesson.
The Format
The eight-hour workshop was broken into three primary sections, each building on top of each other for a deep understanding of the way LLMs are composed. The three sections were Deep Neural Nets / Machine Learning, Architecture, and LLMs. The goal at the end of the day was to have a working version of a GPT2-style LLM. (spoiler alert: I didn’t get all the way there.)
Each section had several chapters, with each chapter having a corresponding .ipynb notebook and Google Sheets workbook. The format was strictly timeboxed for Justin to go through the corresponding slides, followed by a short period of time for us to explore the associated Google Sheet or notebook. In order to fit 23 chapters into an eight hour day, each segment (whether instruction or hands-on exploration) was roughly 5-15 minutes.
Class started promptly at 9. It seemed every minute of the day was very tightly timed. There was a lot of content to cover and it felt at times a bit rushed in order to give us enough time to explore the hands-on materials. My recommendation was to turn this course into a two-day event, with day one being sections one and two - all the way through architecture - and day two focused on pre-training, evaluation and fine-tuning. The added bonus of a two-day workshop is that we could train our own model overnight, since the small model we were building would take about eight hours to train.

Justin used an ongoing analogy of a circuit board with knobs, gates and switches to illustrate the concepts.
Syllabus
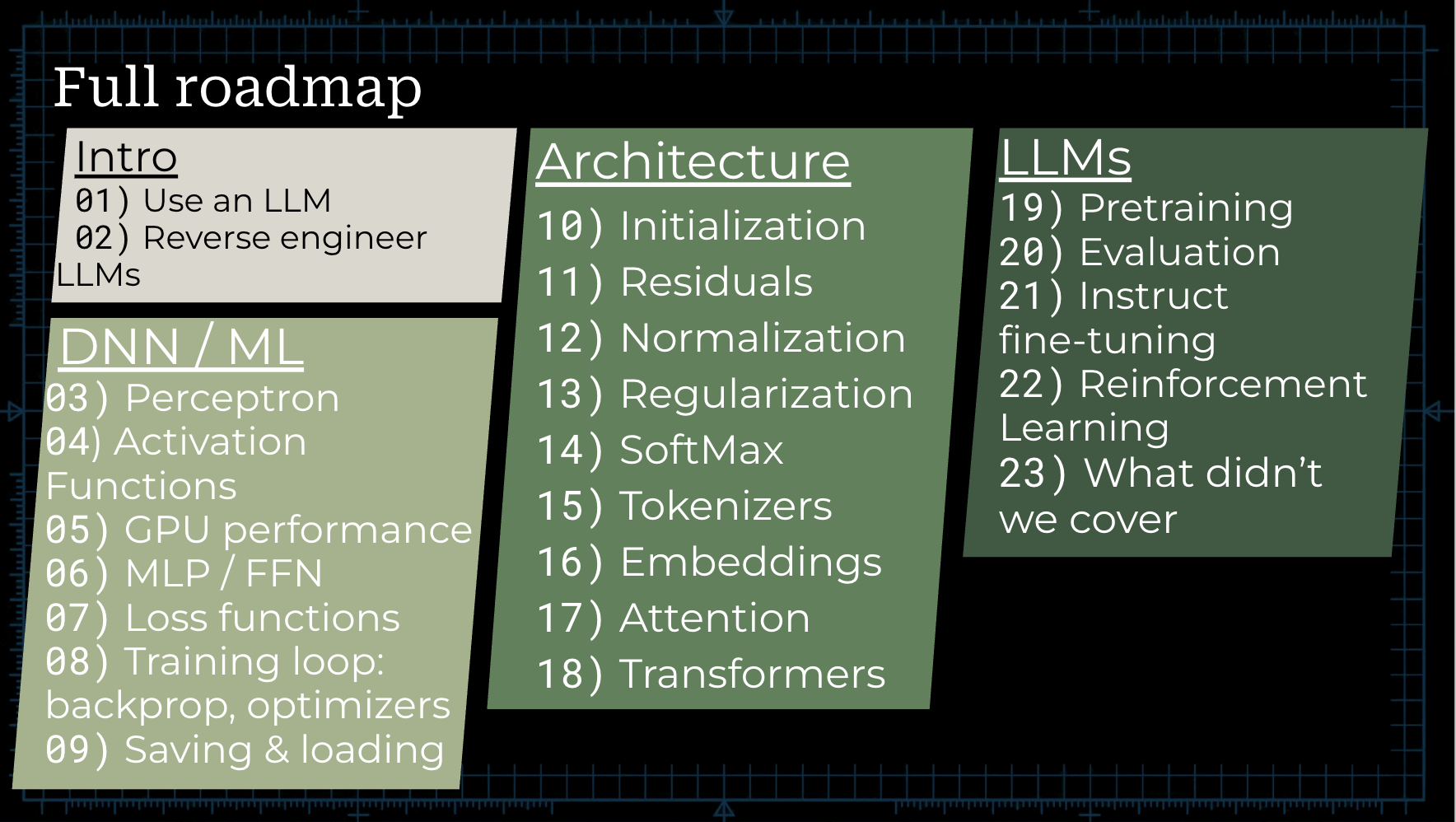
The syllabus for the day was as follows:
Intro
- Intro, and using an LLM
- Reverse Engineering an LLM
DNN & ML
- Perceptron
- Activation Functions
- GPU Performance
- MLP / FFN
- Loss Functions
- Backpropagation
- Saving & Loading
Architecture
- Initialization
- Residuals
- Normalization
- Regularization
- SoftMax
- Tokenizers
- Embeddings
- Attention
- Transformers
LLMs
- Pretraining
- Evaluation
- Instruct fine-tuning
- Reinforcement Learning
- What didn’t we cover?
Every section’s content was covered in the slide deck for the day, with the corresponding hands-on content in a Google Drive.
My Takeaways
The workshop effectively built LLM knowledge up from the most fundamental building blocks. We started with a simple linear algebra equation - Weight * input + bias - which became a matrix multiplication operation when expanded to more dimensions. This led us to activation functions and loss functions. Eventually we were traveling down an N-dimensional gradient to find a minimum. This ties in to building an LLM because minimizing loss helps the model predict the best next token.
The next steps built out the architecture underlying transformers, a key building block of LLMs. These decisions like residuals, normalization and attention can influence how the model performs, although it’s not fully clear how tweaking these architectural choices lead to different outcomes in LLM models - mainly because what the deep neural net is actually doing is still a black box in some ways. We discussed a branch of AI research that was new to me, called mechanistic interpretability. This is the field of research concerned with reverse-engineering what’s happening inside a trained model, for instance, what specific neurons, attention heads and circuits are actually computing. To me, the analogy that makes sense is neuroscience. My understanding is that while we have research explaining what certain parts of the brain do (like the amygdala being related to fear), we can’t pin down exactly what’s happening that makes our brains create our specific thoughts and feelings.
For someone with a math background with a solid fundamental understanding of linear algebra and calculus, I greatly appreciated the overarching framework that built up LLM architecture from these mathematical concepts. For someone with more of a software engineering background, that part might have been more boring or even seem irrelevant. For me, it was a cornerstone to appreciating the mathematical complexity that allows us to build these models.
The machine learning concepts covered towards the middle of the course confused me a little. It didn’t exactly follow my mental model of classical machine learning, which is probably outdated from almost a decade ago. I would’ve loved to see how the mechanics of training a deep neural net compares to simpler machine learning regression and classification models.
By the end of the day, from pre-training through to reinforcement learning, my brain was pretty fried from all the previous concepts. Unfortunately I feel that I didn’t fully grasp how to actually code up, train, and fine-tune an LLM model. I would’ve loved to understand more how to create different variants of a GPT-2 style model by, for instance, messing with the training parameters or fine-tuning differently.
The best part of this workshop is that all the content is still available online for me to refresh my memory at any point. I look forward to completing the hands-on notebooks and Google sheets work from the latter half of the day and eventually training my very own LLM.
On the whole, I thoroughly enjoyed this fast-paced day-long workshop. I would love to take the course again in a more extended format, potentially spanning over two days.
–Em

A fun day packed with lots of heavy-duty new learnings.
References
Content
Master Slide Deck
Hands-On Content: Notebooks and Sheets
Contact
More Events
Rally SF, for more events like this in San Francisco
The Commons Luma Calendar for more events in the space
Learn more about The Commons, a “fourth space” co-working and event space in Hayes Valley where the event was hosted